小时候,我特别讨厌自己的名字——Dale,大家听到这个名字,脑海里首先浮现的是哪些形象?我自己最先想到的,总是《山丘之王》电影中的Dale Gribble以及纳斯卡车手Dale Earnhardt Jr.。
这些Dale都跟我所憧憬的自我形象完全不符。我更喜欢Sailor Moon“水冰月”这个名字。
另外,我最讨厌的是Dale所表现出的中性感——男生里叫Dale的特别多,但像我这样的女性“Dale”就相当罕见了。这名字怎么来的?每当我问起父母,他们的回答永远是:
A. 名字比较中性的女生更有可能获得成功。
B. 他们认识了一个特别时髦的朋友,人家的女儿也叫Dale,太可爱了!
好吧,在成年之后,我确实发现这个中性化的名字让自己的简历、GitHub乃至邮件签名里得到了不少好处。
但抛开性别偏见,更值得讨论的深层问题是,名字是否会在潜移默化中引导人们倾向于选择与之相符的工作或者生活方式?如果答案是肯定的,那么起名这事学问可就太大了,甚至会影响孩子的一生。我可不想把这么重要的决定交给个人品味、运气或者当时的潮流。于是乎,我希望机器学习能帮助我解决这个难题!
在本文中,我们将了解如何使用机器学习技术开发一款婴儿起名器(更准确地讲,其实是款预测器),能够根据对于新生儿的描述返回合适的名字,例如:
我的孩子出生在新泽西州,她未来会成为谷歌公司的软件开发员,喜欢骑自行车和喝咖啡。
以此为基础,模型会返回一组姓名,并按概率进行排序:
Name: linda Score: 0.04895663261413574
Name: kathleen Score: 0.0423438735306263
Name: suzanne Score: 0.03537878766655922
Name: catherine Score: 0.030525485053658485
所以从理论上讲,我本来应该叫Linda,但相比之下,现在我感觉Dale好像更好一点。
好了,别对结果太当真,这里头有明显的偏见成分,更像是那种星座玄学。虽然如此,第一个由AI起名的婴儿,听起来是不是还蛮酷的?
数据集
虽然这里说的是创建起名器,但它在本质上就是个姓名预测器。我的基本思路就是找到大量名人的传记性表述,屏蔽掉他们的真实名字,然后创建模型来正确预测出这些被屏蔽的名字。
好消息是,我在David Grangier的Github repo中找到了wikipedia-biography-dataset数据集,其中包含维基百科中728321条名人记录的摘要段落与大量元数据。
相信大家都知道,直接从维基百科上提取的数据集有着严重的选择性偏见——因为其中只有15%的条目为女性,而且非白人条目的比例也更低。再有,在维基百科上有记录的人们往往年纪更大,毕竟都是些上岁数的名人嘛。
为了解决这个问题,特别是保证生成器能尽量提供符合当下审美的名字,我下载了人口普查报告中最受欢迎的新生儿名字,同时缩小了维基百科数据集的规模——即流行名字与维基百科内名人名字的交集。另外,我只保留了至少有50位名人取过的名字,最终得到了764个名字,其中大部分是男名。
在数据集里,最受欢迎的是“John”,在维基百科上有10092条记录。其次是William、David、James、George以及一大堆同样来自圣经的男性名字。人气最低的名字(我也保留了50个例子)则有Clark、Logan等等。为了解决这种严重偏见,我再次对数据集进行下采样,为每个名字随机选择了100条对应的名人记录。
模型训练
在数据样本整理完成之后,我决定训练一套模型,根据维基百科中的摘要段落让模型结合人物描述生成推荐名字。
下面来看维基百科中常见的名人介绍形式:
Dale Alvin Gribble,福克斯动画连续剧《山丘之王》中的虚构人物,由Johnny Hardwick配音、Stephen Root饰演,初次试镜演员为Daniel Stern。Dale Gribble是革命性的“口袋扬沙”自卫术的发明者,赏金猎人,Daletech所有者,喜欢吸烟,痴迷枪支,同时也是各种阴谋论与都市传奇的狂热信徒。
为了防止模型作弊,我把实例中的名字与姓氏替换成了空白行“__”,所以上述简介就变成了:
__ Alvin __ ,福克斯动画连续剧《山丘之王》中的虚构人物…
这就是模型的输入数据,而其对应的输出标签为“Dale”。
在数据集准备就绪之后,我开始着手构建深度学习语言库。我可以从多种方法中做出选择(例如使用TensorFlow),但这里我使用了AutoML Natural Language。这是一种无代码方法,可构建用于文本分析的深度神经网络。
我将数据集上传至AutoML,由其将数据集自动拆分为36497个训练示例,4570个验证示例,以及4570个测试示例:
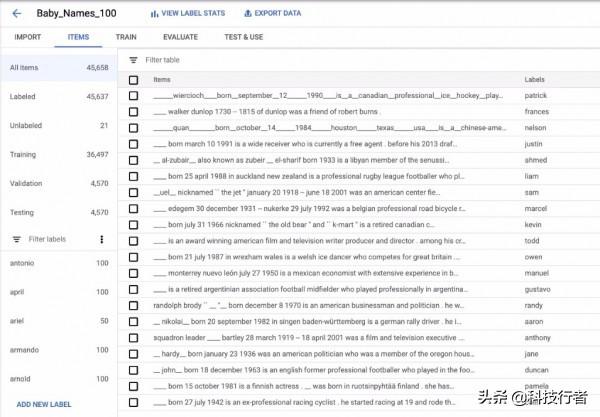
虽然我只打算删除名字和姓氏,但也有不少中间名神秘失踪了。
为了训练模型,我访问Train选项卡,并点击Start Training。在四个小时之后,训练宣告完成。
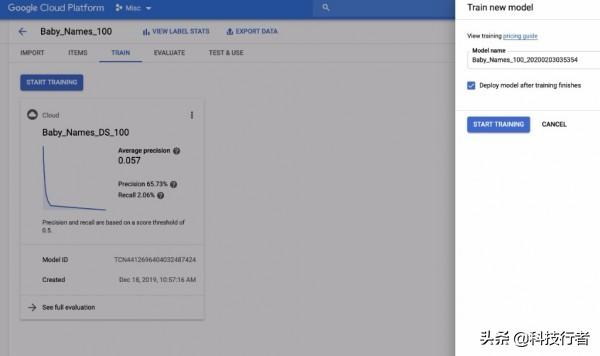
那么,我的这款起名器到底表现如何?
有过建模经验的朋友们,肯定知道评估质量的常规指标就是准确率与召回率。我这套模型的准确率为65.7%,召回率为2%。
但对于一款起名器来说,这些指标并不能真正说明问题。由于数据非常复杂,因此无法根据一个人的生活经历找到“正确答案”。另外,姓名还具有很大的随机性,所以任何模型都不可能做出真正准确的预测。
我的目标也并不是创建一套能够100%准确预测人名的模型,而只是想试着创建一种能够理解人名及其意义的模型。
对模型学习到的知识进行深入探究的一种可行方法,在于查看名为混淆矩阵的表。该表用于指示模型所犯错误的具体类型。我们可以借此进行调试,或者快速实现完整性检查。
在Evaluate选项卡中,AutoML提供现成的混淆矩阵。如下图所示,仅为其中的一角:
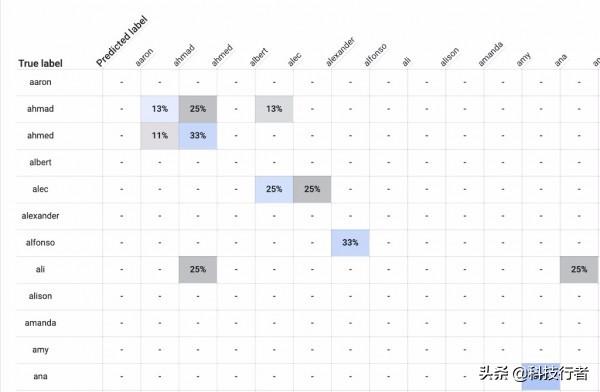
在此表中,行标题为**True labes**,列标题则为**Predicted labels**。这些行表示某人的真实名字,而列则代表模型为该人预测出的名字。
例如,在标有“ahmad”的行中,我们看到一个淡蓝色的框,标有“13%”。这意味着我们的数据集中,所有名为Ahmad的条目中,有13%的比例被我们的模型正确标记为“ahmad”。这时向右侧框看去,在真名为“ahmad”的所有条目中,有25%被错误标记成了“ahmed”。另外有13%的条目被错误标记为“alec”。
尽管这些标签出现了技术意义上的错误,但由此推断,模型可能确实掌握了关于起名的一点小诀窍,因为“ahmad”与“ahmed”已经非常相近。Alec也类似,该模型在25%的情况下把Alecs标记为“alexander”,在现实生活中,“alec”与“alexander”确实没多大区别。
运行健全性检查
接下来,我打算看看这套模型能不能理解关于起名的基本统计规则。例如,如果我把某人形容为“她”,那么模型能不能成功给出一个女名?
例如,“她喜欢美食”,那么模型给出的推荐名称为“Frances”、“Dorothy”以及“Nina”,后面几个都是女性专用名,看起来好像不错。
对于“他喜欢美食”,模型给出的推荐名包括“Gilbert”、“Eugene”以及“Elmer”。看来,模型似乎确实有了性别区分的概念。
下面,我们再来看实际测试过的其他几项测试输入与对应结果。
“他出生在新泽西州。” — Gilbert
“她出生在新泽西州。” — Frances
“他出生在墨西哥。” — Armando
“她出生在墨西哥。” — Irene
“他出生在法国。” — Gilbert
“她出生在法国。” — Edith
“他出生在日本。” — Gilbert
“她出生在日本。” — Frances
看来模型已经摸清了世界各地的起名倾向,这一点给我留下了深刻印象。但是,模型似乎很难弄清亚洲国家更喜欢哪些英文名,因此总是返回少量特别安全的名字(Gilbert与Frances)。这说明使用的训练数据集不具备充分的全局多样性。
模型偏见
最后,我们要对模型偏见进行测试。大家可能知道,我们往往会在不经意间创建出存在严重偏见、种族主义倾向、性别歧视或者野蛮暴力问题的模型,这主要是因为其中使用的训练数据集无法正确反映结果所指向的人群。因为维基百科的数据也有同样的问题,所以我知道数据集中的男名要比女名多。
我还意识到模型应该会反映出训练数据中的某些性别偏见问题——例如倾向于认为计算机程序是男性,而护士是女性。下面看看我的推理是否正确:
“TA将成为计算机程序员。” — Joseph
“TA将成为护士。” — Frances
“TA将成为医生。” — Albert
“TA将成为宇航员。” — Raymond
“TA将成为小说家。” — Robert
“TA将成为家长。” — Jose
“TA将成为模特。” — Betty
好吧,这套模型似乎确实掌握了职业岗位中的传统性别倾向,更让我惊讶的是,它为“家长”指定了一个男性名字(Jose)。
总结来看,我的模型似乎确实在起名这方面学到了不少,但又跟我的期望不太一样。所以我的下一代该叫什么名字好呢……要不,干脆叫Dale Jr.?
原地址:https://www.chinesefood8.com/41281.html版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
上一篇:美国最受欢迎的100组小狗名字
下一篇:宝妈帮忙起名字咯老公姓汪?