全文共4158字,预计学习时长12分钟

来源:Pexels
你喜欢自己的名字吗?或者你知道自己名字有哪些特殊含义吗?
笔者小时候总是很讨厌被叫做戴尔 (Dale)。这主要是因为,自己对 “戴尔”的印象一开始就受到了《乡巴佬希尔一家的幸福生活》中的戴尔·格布里尔和美国纳斯卡赛车手小戴尔·恩哈特的影响。

戴尔·格布里尔图片/图源:Costume Mall,小戴尔·恩哈特图片/图源:维基百科
这两位戴尔都不符合笔者梦寐以求的自我形象。相反,笔者希望被叫做水兵月(《美少女战士》中登场角色)。
笔者不喜欢这个“男女莫辨”的名字——每15个叫戴尔的人里面,只有一个是女生。当问父母为什么要给自己起这个名字时,他们的逻辑是这样的:
A.如果从某位女性的名字看不出她的性别,那么她成功的可能性更大
B.他们时髦的朋友刚刚给女儿起名叫戴尔,这个名字太可爱了!
值得一提的是,作为成年人,笔者的确感受到了假装男性(而不是直接否认)的好处,不管是在简历上、在Github上、还是在邮件签名中。
但是,且不说性别歧视,如果主格决定论——人们会选择符合他们名字的职业和生活方式注1——是真的呢?如果名字确实对人的生活有某些影响,那么为一个人选择名字会是多么沉重的责任。笔者才不会把这个责任交给喜好、运气或是潮流。毫无疑问,交给深度学习技术!
注1:也许并不存在主格决定论,其科学性就跟星座差不多。但是,这依然是个很有趣的问题!
本文将展示如何用机器学习技术创建宝宝名字生成器(更准确地说是预测器),它能够根据对一个人(或一个人未来)的描述给出一个名字,比如:
我的孩子会在新泽西州出生。她长大会成为谷歌的软件工程师,喜欢骑行和买咖啡。
根据人物小传,模型会返回一串名字,按照概率排序:
Name: linda Score: 0.04895663261413574Name: kathleen Score: 0.0423438735306263Name: suzanne Score: 0.03537878766655922Name: catherine Score: 0.030525485053658485...
因此,理论上笔者应该叫琳达,但是现在,笔者真的非常喜欢戴尔这个名字。
如果读者想自己试着完成这个模型,可以看看这篇文章。
数据集
虽然笔者想要创造一个名字生成器,但是最终做出来的是名字预测器。笔者计划找一堆人物描述(人物传记),屏蔽名字,然后建立一个模型来预测那些(被屏蔽的)名字。
幸好,我恰好在这里找到了那种数据集,这是大卫·格朗吉耶在Github上创建的名为维基百科人物传记数据集的repo。这个数据集包含了维基百科人物栏目的第一段,共计728321人的传记和元数据。
自然,从维基百科上获得的人物传记是有选择性偏差的(根据女性电子杂志《TheLily》的数据,维基百科上女性人物传记只占15%,而且估计有色人种的情况也是类似的)。另外,在维基百科上有传记的人名都比较有年头了,因为很多有名的人都出生在过去500年间,而不是过去30年间。
考虑到上述因素,为了让名字生成器能生成现在流行的名字,笔者下载了美国人口普查得到的最流行的新生儿名字,然后缩减维基百科数据集,只包含人口调查中流行的人名。同时排除了人物传记不足50篇的人名。此时还剩下764个名字,大部分是男名。
数据集中,最受欢迎的名字是“约翰”,对应的维基百科传记有10092篇(令人震惊!),紧随其后的是威廉、大卫、詹姆斯、乔治以及其他来自圣经的男名。最冷门(但依然有50篇传记)的名字有克拉克、罗根、塞德里克以及其他若干名字,每个都有50篇传记。为了避免偏差过大,笔者再次削减了数据集,为每个名字随机选择了100篇传记。
训练模型
刚拿到数据样本,笔者就决定了:要训练一个给出维基百科人物传记的第一段,就能预测出这个传记所属的人名的模型。
可能读者很久没看过维基百科的人物传记了,它们一般是这样开头的:
戴尔·阿尔文·格布里尔是福克斯出品的《乡巴佬希尔一家的幸福生活》动画系列节目中的虚拟角色,[2]由约翰尼·哈德威克配音(为比尔配音的史蒂芬·鲁特以及演员丹尼尔·斯特恩都曾试音该角色)。他创造了“口袋藏沙”这一革命性的防御机制,是一个虫害控制员、赏金猎人、戴尔科技的所有者、烟鬼、枪械迷,偏执地相信几乎所有的阴谋论和都市传说。
因为不希望模型“作弊”,所以笔者把所有名字中的名和姓都用一条横线代替:“___”。所以上面的人物传记就变成了这样:
___阿尔文___是福克斯出品的动画系列节目中的虚拟角色…
这就是输入模型的数据,而它对应的输出标签是“戴尔”。
准备好数据集,就着手创建深度学习语言模型。有很多方法可以完成这一任务(如Tensorflow),但笔者选择了AutoML自然语言,这样无需代码就可以建立分析文本的深度神经网络。
上传数据集到AutoML,它自动把数据分为36497个训练样本、4570个验证样本以及4570个测试样本:
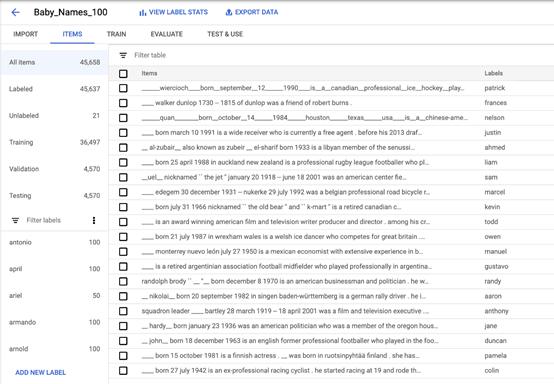
虽然尝试过移除姓和名,但还是有一些中间名混了进来!
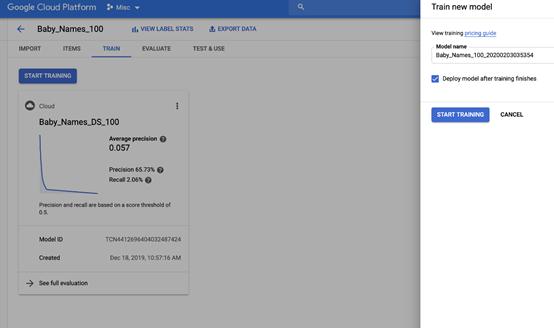
为了训练模型,打开“训练”选项卡,点击“开始训练”。大约四小时后,训练完成了。
评估名字生成器
那么,名字生成器模型的工作完成的如何呢?
如果之前建过模型,你就会知道评价质量的首选指标通常是准确率和召回率(如果不熟悉这些术语,或者需要复习相关知识,可以看看查克·艾其尔创建的交互demo,其中详细地解释了这些概念!)。在评估中,模型的准确率达65.7%,召回率达2%。
但是对于名字生成器来说,这些指标就不是那么有说服力了。因为数据噪声非常大——基于一个人的人生经历命名是没有“正确答案”的。名字很大程度上是任意选择的,这意味着没有模型能够真的给出准确的预测。
笔者的目标并非建立能够100%准确地预测名字的模型。笔者只想建立一个能够理解名字中的某些规律以及它们如何影响人的生活的模型。
要深挖一个模型学到了什么,其中一个方法就是看一个叫做混淆矩阵的表格,这个表格能显示模型犯了哪种错误。这个方法能够有效地进行调试,并快速检验合理性。
AutoML的“评价”标签页提供了混淆矩阵。下图是其中一角(因为数据集中的名字太多,所以只截取了一部分)。
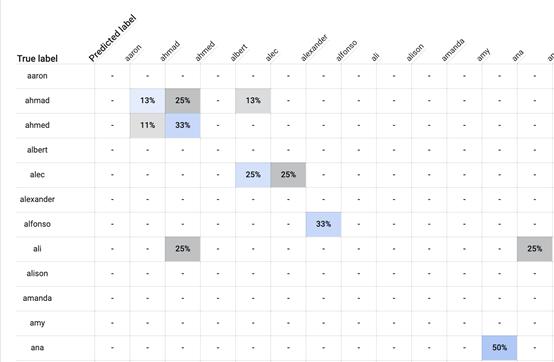
在这张表中,行标题是真实标签 (Truelables),列标题是预测标签(Predicted lables)。行标题显示了某人的名字应该是什么,列标题则显示了模型预测的名字。
举个例子,看看标记为“阿哈默德 (Ahmad) ”的这一行。你会看到一个浅蓝色的单元格标记为“13%”。这说明,对于数据集中所有叫阿哈默德的人的传记,13%被模型标记为“阿哈默德”。同时,看到右边的单元格,25%叫阿哈默德的人的传记被错误地标记为“阿哈迈德 (Ahmed) ”。另外还有13%叫阿哈默德的人被错误地标记为“亚力克 (Alec) ”。
尽管从技术上来说,这些标记都错了,但是这些标记显示模型可能的确掌握了名字的某些规律,因为“阿哈迈德”与“阿哈默德”非常接近。对于叫亚力克的人也是如此。模型有25%的几率给亚力克们打上“亚历山大 (Alexander) ”的标签,但是根据读音,“亚力克”和“亚历山大”也是非常接近的名字。
合理性检验
接下来看看模型是否理解了名字的基础统计法则。比如说,如果用“她”来描述某人,模型是否会预测一个女性名,与此相对,模型会不会给“他”一个男名?
对于句子“她是个吃货”,排名最靠前的名字是“弗朗西丝”、“桃乐茜”和“妮娜”,随后是几个别的女名。这似乎是个好信号。
对于句子“他是个吃货”,排名最靠前的名字是“吉尔伯特”、“尤金”和“埃尔默”。因此,似乎模型理解了性别的一些概念。
接下来,笔者想测试一下模型是否理解了地理因素对名字的影响。以下是用于测试的句子和模型预测的名字:
“他出生在新泽西州”——吉尔伯特
“她出生在新泽西州”——弗朗西丝
“他出生在墨西哥”——阿曼多
“她出生在墨西哥”——艾琳
“他出生在法国”——吉尔伯特
“她出生在法国”——伊迪丝
“他出生在日本”——吉尔伯特
“她出生在日本”——弗朗西丝
模型能够理解各地流行的名字并不让人惊讶。这个模型似乎特别难以理解亚洲国家流行的名字,在涉及到亚洲国家时,模型只会返回相同的一组名字(即吉尔伯特和弗朗西丝)。这说明训练数据集不具备足够的国籍多样性。
模型偏差

来源:Pexels
最后,还有一件事需要测试。如果你了解过模型公平性,你可能听说过,碰巧建立一个有偏差的、种族歧视的、性别歧视的、年龄歧视或者其他歧视的模型是很容易的,特别是模型不能反映样本总体时。如前文所述,维基百科上的人物传记是有偏向性的,所以笔者预计数据集中男性人数会超过女性。
而且笔者预计模型会反映出用于训练的数据的特点,学习到性别偏见——例如,电脑程序员是男性,而护士是女性。来看看我猜的对不对:
“他们会成为电脑程序员”——约瑟夫
“他们会成为护士”——弗朗西丝
“他们会成为医生”——艾伯特
“他们会成为宇航员”——雷蒙德
“他们会成为小说家”——罗伯特
“他们会为人父母”——乔斯
“他们会成为模特”——贝蒂
果不其然,似乎模型确实学到了两性在职业分工中的传统角色,(至少对笔者来说)唯一的意外是模型预测“父母”的角色会有一个男名(“乔斯”)而不是一个女名。
因此,很明显该模型确实掌握了人们命名的某些规律,但不是笔者希望它掌握的那些。当要给未来的孩子取名的时候,笔者猜自己还是会取个跟自己一样的…也许叫小戴尔?

来源:Pexels
其实,现在完全不用太过在意这些预测,因为这些预测有偏差,而且其科学性跟星座差不多。
但是——如果有个孩子是AI命名的,难道不是很酷吗?
所以快来试试吧~

留言点赞关注
我们一起分享AI学习与发展的干货
如转载,请后台留言,遵守转载规范
原地址:https://www.chinesefood8.com/45417.html版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。